Spark定义:
Spark编程始于数据集,而数据集往往存放在分布式持久化存储之上,比如Hadoop分布式文件系统HDFS
编写Spark 程序通常包括一系列相关步骤。
• 在输入数据集上定义一组转换。
• 调用 action,用以将转换后的数据集保存到持久存储上,或者把结果返回到驱动程序的
本地内存。
• 运行本地计算,本地计算处理分布式计算的结果。本地计算有助于你确定下一步的转换
和 action。
要想理解 Spark,就必须理解 Spark 框架提供的两种抽象:存储和执行。Spark 优美地搭配
这两类抽象,可以将数据处理管道中的任何中间步骤缓在内存里以备后用
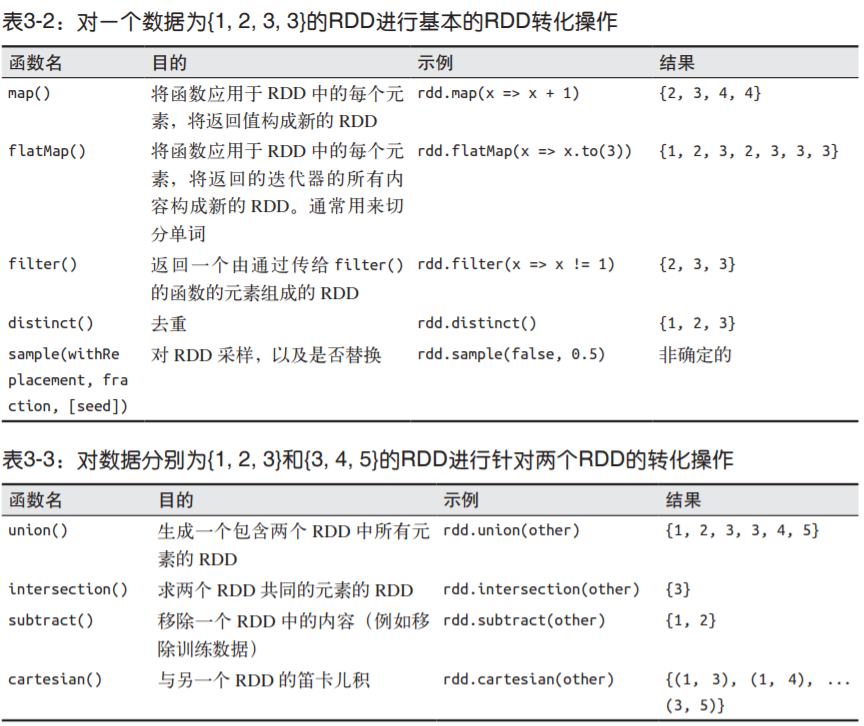
常见的RDD转化操作
transform算子:
action算子:

case class
case class 是不可变类的一种简单类型它非常好用,内置了所有 Java 类的基本方法,比如toString、equals和 hashCode。我们来试试为记录关联数据定义一个 case class:
数据分析
1 | 样例数据来自加州大学欧文分校机器学习资料库(UC Irvine Machine Learning Repository)。 |
数据获取
$ mkdir linkage
$ cd linkage/
$ wget https://archive.ics.uci.edu/ml/machine-learning-databases/00210/donation.zip
(http://bit.ly/1Aoywaq)
$ unzip donation.zip
$ unzip 'block_*.zip'
放入HDFS:
$ hadoop fs -mkdir /linkage
$ hadoop fs -put block_*.csv /linkage
启动spark-shell 这里本地启动
spark-shell
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
19/05/24 07:15:36 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Spark context Web UI available at http://192.111.110.111:4040
Spark context available as 'sc' (master = spark://master:7077, app id = app-20190524071537-0001).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.2.0
/_/
Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_144)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
如果出现以上说明启动成功
读数据
scala>val rawblocks = sc.textFile("hdfs:///linkage/*.csv")
scala>val head = rawblocks.take(10)
scala>head.length
res2: Int = 10
遍历
scala>head.foreach(println)
"id_1","id_2","cmp_fname_c1","cmp_fname_c2","cmp_lname_c1","cmp_lname_c2","cmp_sex","cmp_bd","cmp_bm","cmp_by","cmp_plz","is_match"
37291,53113,0.833333333333333,?,1,?,1,1,1,1,0,TRUE
39086,47614,1,?,1,?,1,1,1,1,1,TRUE
70031,70237,1,?,1,?,1,1,1,1,1,TRUE
84795,97439,1,?,1,?,1,1,1,1,1,TRUE
36950,42116,1,?,1,1,1,1,1,1,1,TRUE
42413,48491,1,?,1,?,1,1,1,1,1,TRUE
25965,64753,1,?,1,?,1,1,1,1,1,TRUE
49451,90407,1,?,1,?,1,1,1,1,0,TRUE
39932,40902,1,?,1,?,1,1,1,1,1,TRUE
定义函数过滤第一行的表头数据:(“id_1”,”id_2”,”cmp_fname_c1”….)
scala> def isHeader(line:String):Boolean={
line.contains("id_1") || line.contains("cmp")
}
scala> head.filter(isHeader).foreach(println) 查包含"id_1"的行
scala> head.filterNot(isHeader).foreach(println) 查不包含"id_1"的行
scala> head.filter(x=> isHeader(x)).foreach(println) 查包含"id_1"的行
scala> head.filter(x=> !isHeader(x)).foreach(println) 查不包含"id_1"的行
scala> head.filter(isHeader(_)).foreach(println) 查包含"id_1"的行
scala> head.filter(!isHeader(_)).foreach(println) 查不包含"id_1"的行
过滤的方法有三种,再上方已经列举出来了,可以根据喜好和编码习惯选择
将去掉标题头 即含有 id_1的第一行去掉后变为新的 RDD
scala> val noheader = rawblocks.filter(x => !isHeader(x))
noheader: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[4] at filter at <console>:28
进行数据结构化
说到数据结构化,首先java的思想就是封装,scala中是元组和case class ,其中 case class类似于封装
tuple 元组 -- scala
为了测试方便,先取一行数据
val line = head(5)
1. 首先定义一个函数,里面处理每一行数据
def parse(line:String)={
val pieces = line.split(',')
val id1 = pieces(0).toInt
val id2 = pieces(1).toInt
val scores = pieces.slice(2,11).map(toDouble)
val matched = pieces(11).toBoolean
(id1,id2,scores,matched)
}
val tup = parse(line)
2. 可能你没有注意有问号的情况,那么为了避免出现 ? 导致程序报错,可以定义 toDouble函数
def toDouble(s:String)={
if("?".equals(s)) Double.NaN else s.toDouble
}
--------------------------------------------------------------------------
slice函数截取集合
slice函数需要两个参数,第一个参数表示从该下标开始截取,第二个参数表示截取到该下标(不包含)。
object TestCollection {
val list =List(1,4,6,4,1)
def main(args: Array[String]): Unit = {
print(list.slice(0,3))
}
}
--------------------------------------------------------------------------
3. 之后再执行 val tup = parse(line)
得到的tup就是一个元组
元组的操作:
tup._1 取第一个元素
tup.productElement(0) 或者用 productElement 方法,它是从 0 开始计数的。
tup.productArity 也可以用 productArity 方法得到元组的大小
case class
case class 是不可变类的一种简单类型,它非常好用,内置了所有 Java 类的基本方法,比如 toString、equals 和 hashCode。我们来试试为记录关联数据定义一个 case class:
case class MatchData(id1: Int, id2: Int,scores: Array[Double], matched: Boolean)
现在修改 parse 方法以返回 MatchData 实例,这个实例是 case class 而不再是元组:
def parse(line: String) = {
val pieces = line.split(',')
val id1 = pieces(0).toInt
val id2 = pieces(1).toInt
val scores = pieces.slice(2, 11).map(toDouble)
val matched = pieces(11).toBoolean
MatchData(id1, id2, scores, matched)
}
val md = parse(line)
这里要注意两点:
一,创建 case class 时没必要在 MatchData 前写上关键字 new
二,MatchData 类有个内置的 toString 方法实现,除了scores 数组字段外,这个方法在其他字段上的表现都还不错。
现在通过名字来访问 MatchData 的字段:
md.matched
md.id1
是不是有种 对象.成员变量 的意思 有些地方还是很像java的,比如java8的lambda表达式和scala非常相似
之后将其作用于head数据集上
val mds = head.filter(x=> !isHeader(x)).map(x=> parse(x))
之后再作用于整个数据集上 noheader
val parsed = noheader.map(line => parse(line))
记住:和我们本地生成的 mds 数组不同,parse 函数并没有实际应用到集群数据上。当在
parsed 这个 RDD 上执行某个需要输出的调用时,就会用 parse 函数把 noheader RDD
的每个 String 转换成 MatchData 类的实例。如果在 parsed RDD 上执行另一个调用以
产生不同输出,parse函数会在输入数据上再执行一遍。这没有充分利用集群资源。数据一
旦解析好,我们想以解析格式把数据存到集群上,这样就不需要每次遇到新问题时都重新解
析。Spark支持这种使用场景,通过在实例上调用cache 方法,可以指示在内存里缓存某个
RDD。现在用 parsed 这个 RDD 实验一下:
parsed.cache()
Spark的缓存:
虽然默认情况下 RDD 的内容是临时的,但 Spark 提供了在 RDD 中持久化数据的机制。第
一次调用动作并计算出 RDD 内容后,RDD 的内容可以存储在集群的内存或磁盘上。这样下一
次需要调用依赖该 RDD 的动作时,就不需要从依赖关系中重新计算 RDD,数据可以从缓存分
区中直接返回:
cached.cache()
cached.count()
cached.take(10)
在上述代码中,cache 方法调用指示在下次计算 RDD 后,要把 RDD 存储起来。调用
count 会导致第一次计算 RDD。采取(take)这个动作返回一个本地的 Array,包含
RDD 的前 10 个元素。但调用 take 时,访问的是 cached 已经缓存好的元素,而不是
从 cached 的依赖关系中重新计算出来的。
Spark 为持久化 RDD 定义了几种不同的机制,用不同的 StorageLevel 值表示。rdd.
cache() 是 rdd.persist(StorageLevel.MEMORY) 的简写,它将 RDD 存储为未序列化
的 Java 对象。当 Spark 估计内存不够存放一个分区时,它干脆就不在内存中存放该分
区,这样在下次需要时就必须重新计算。在对象需要频繁访问或低延访问时适合使用
StorageLevel.MEMORY,因为它可以避免序列化的开销。相比其他选项,StorageLevel.
MEMORY 的问题是要占用更大的内存空间。另外,大量小对象会对 Java 的垃圾回收造成
压力,会导致程序停顿和常见的速度缓慢问题。
Spark 也提供了 MEMORY_SER 的存储级别,用于在内存中分配大字节缓冲区以存储 RDD
序列化内容。如果使用得当(稍后会详细介绍),序列化数据占用的空间比未经序列化
的数据占用的空间往往要少两到五倍。
Spark 也可以用磁盘来缓存 RDD。
存储级别 MEMORY_AND_DISK 和 MEMORY_AND_DISK_SER
分别类似于 MEMORY 和 MEMORY_SER。对于 MEMORY 和 MEMORY_SER,如果一个分区在内存
里放不下,整个分区都不会放在内存。对于 MEMORY_AND_DISK 和 MEMORY_AND_DISK_SER,
如果分区在内存里放不下,Spark 会将其溢写到磁盘上。
什么时候该缓存数据是门艺术,这通常需要对空间和速度进行权衡,垃圾回收开销的
问题也会时不时让情况更复杂。一般情况下,如果多个动作需要用到某个 RDD,而它
的计算代价又很高,那么就应该把这个 RDD 缓存起来。
聚合
我们用 groupBy 方法来创建一个 Scala Map[Boolean, Array[MatchData]],其中键值基于MatchData 类的字段 matched:
val grouped = mds.groupBy(md => md.matched)
grouped: scala.collection.immutable.Map[Boolean,Array[MatchData]] = Map(true -> Array(MatchData(37291,53113,[D@14587d48,true), MatchData(39086,47614,[D@556e8e2e,true), MatchData(70031,70237,[D@4d94e219,true), MatchData(84795,97439,[D@25937e5b,true), MatchData(36950,42116,[D@7276f59c,true), MatchData(42413,48491,[D@53481a02,true), MatchData(25965,64753,[D@3926be58,true), MatchData(49451,90407,[D@7f96e81,true), MatchData(39932,40902,[D@42e6a1f7,true)))
利用mapValues进行记数
grouped.mapValues(x=>x.size).foreach(println)
(true,9)
创建直方图
先来试试创建一个简单的直方图,用它来算一下 parsed 中的 MatchData 记录有多少 matched
字段值为 true 或 false。幸运的是 RDD[T] 类已经定义了一个名为 countByValue 的动作,该
动作对于计数类运算效率非常高,它向客户端返回 Map[T,Long] 类型的结果。对 MatchData
记录中的 matched 字段映射调用 countByValue 会执行一个 Spark 作业,并向客户端返回结果:
scala> val matchCounts = parsed.map(md => md.matched).countByValue()
countByValue:统计一个RDD中各个value的出现次数。返回一个map,map的key是元素的值,value是出现的次数。
count: 统计RDD中元素的个数。
countByKey: 与count类似,但是是以key为单位进行统计。 注意:此函数返回的是一个map,不是int。
Scala 的Map 类没有提供根据内容的键或值排序的方法,但是我们可以将 Map 转换成Scala 的Seq 类型,而Seq 支持排序。
Scala 的 Seq 类和 Java 的 List 类接口类似,都是可迭代集合,即具有确定的长度并且可以根据下标来查找值。
scala> val matchCountsSeq = matchCounts.toSeq
matchCountsSeq: Seq[(Boolean, Long)] = ArrayBuffer((true,20931), (false,5728201))
------------------------------------------------------------------------------------------------
Scala 集合
Scala 集合类库很庞大,包括 list、set、map 和 array。利用 toList、toSet 和 toArray
方法,各种集合类型可以方便地相互转换。
------------------------------------------------------------------------------------------------
sortBy 排序
matchCountsSeq.sortBy(_._1).foreach(println)
matchCountsSeq.sortBy(_._2).foreach(println)
matchCountsSeq.sortBy(_._2).reverse.foreach(println)
_._1 指按第一列指标排序
reverse 反转排序结果